
TL;DR
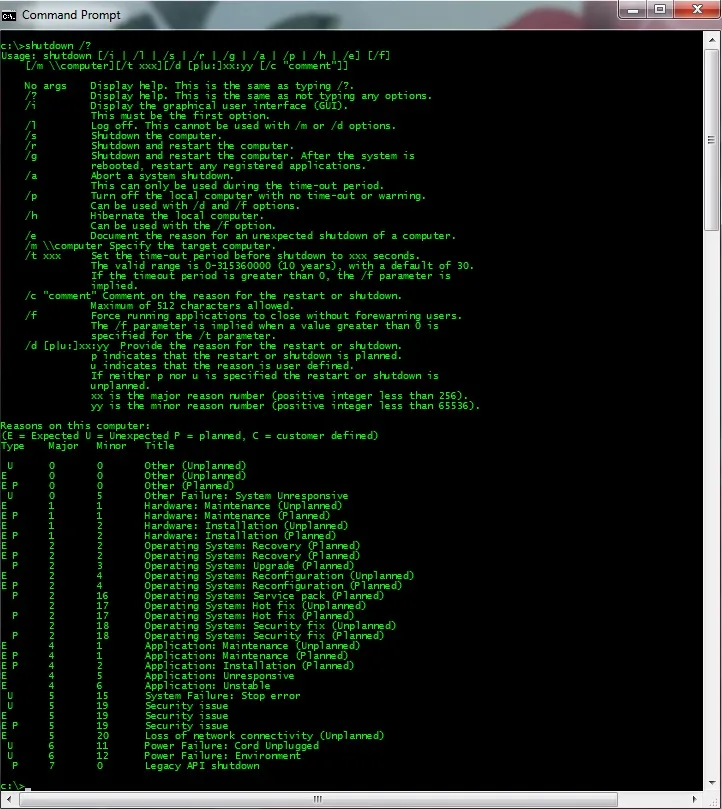
Microsoft Windows 7 operating system, as well as previous versions of Windows OS, comes with a built-in shutdown command which among other things enables the user to initiate a shutdown procedure. By entering the shutdown /? command inside CMD (Command Prompt) you can see the complete help and usage information.
Figure 1. Help and usage for shutdown command
If we take a look at the list of possible switches we can see that the /i switch is responsible for displaying the graphical user interface (GUI). So let's enter the shutdown /i command and see what will happen.
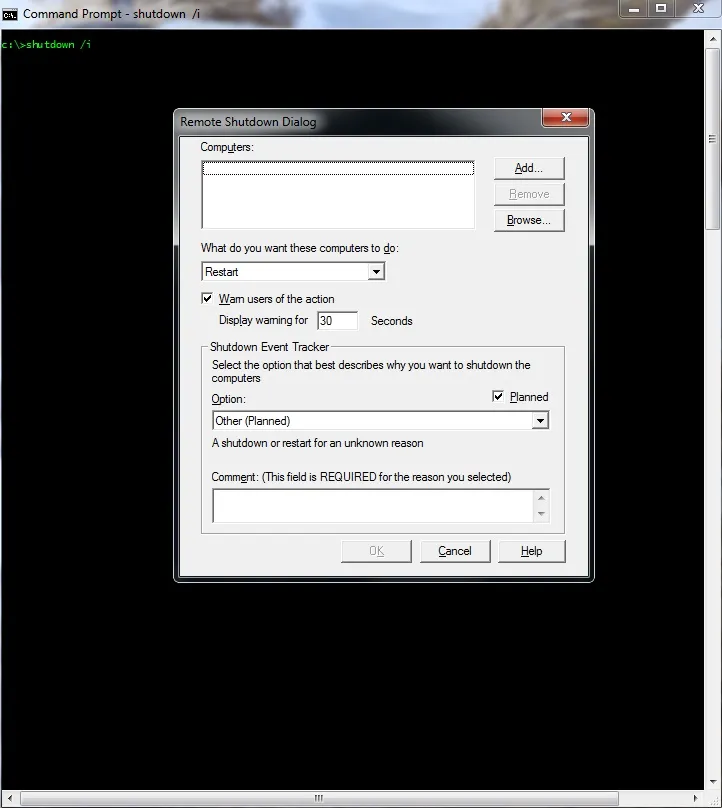
Figure 2. Graphical User Interface for shutdown command
As you can see, we are presented with a GUI interface inside which we can easily tell shutdown command what we want it to do. To tell the command which computer/computers we want to include, we simply click on „Add…“ button and then we can enter the computer name or its IP address.
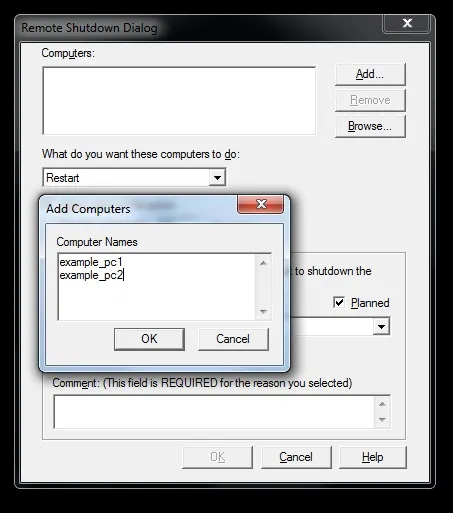
Figure 3. Adding computers to be used with shutdown command
Once we're done with adding computers to our list, we can tell shutdown command what exactly do we want it to do with those computers.
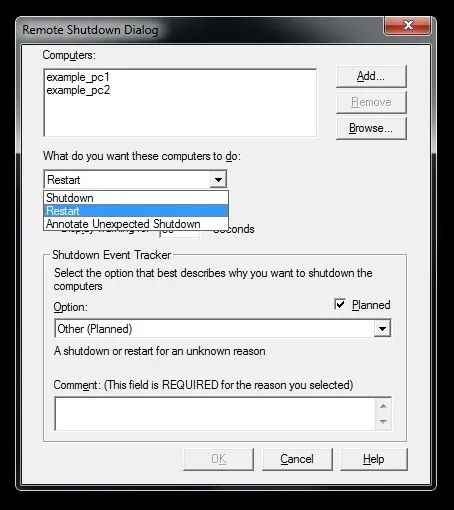
Figure 4. Selecting required action
We can see on Figure 4. that we can either choose to shutdown selected computers, restart them, or annotate unexpected shutdown.
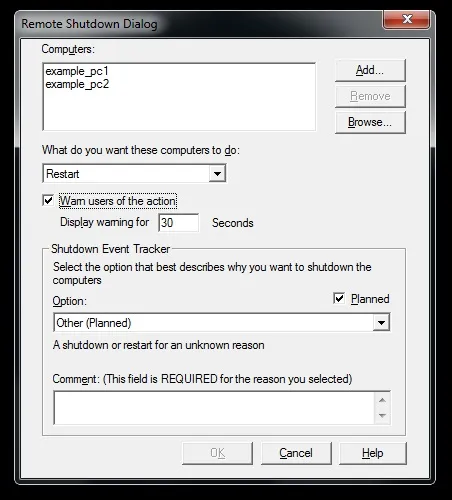
Figure 5. Deciding whether we want to alert users that shutdown is in progress or not.
If "Warn users of the action" checkbox is checked, then users logged on selected computers will receive a message that shutdown is in progress and that their computer will shutdown when "Display warning for" value reaches zero. The maximum value that can be set is 999 seconds.
Under "Shutdown Event Tracker" section we can set one of pre-defined planned or unplanned options.

Figure 6. Setting planned reason for a shutdown.
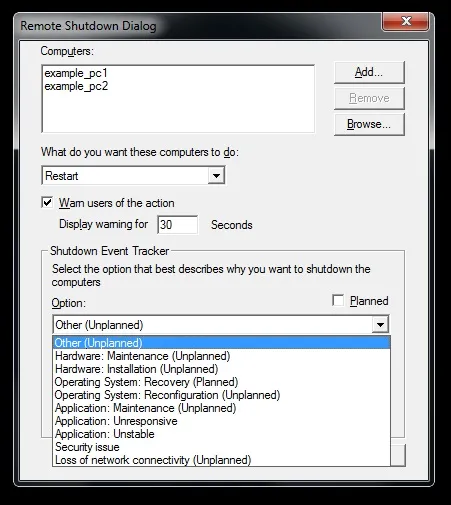
Figure 7. Setting unplanned reason for a shutdown.
Once we set the adequate option, all that is left for us to do is to fill the "Comment:" field. In this field, we can explain the reason for the shutdown in more depth.

Figure 8. Entering user comment.
Once we reach this stage, all we have to do is to press the "OK" button and the shutdown command will be executed. It is important to say that shutdown command requires administrator privileges to run. So if you plan to execute the shutdown command on a remote computer, you'll need to have administrator privileges on that specific computer.




