
TL;DR
In today’s information age, IT security is a necessary issue to consider. Operating systems vendors have developed numerous built-in features to prevent, detect, and investigate security incidents that happened to their systems. Windows auditing policy is a part of this endeavor.
Windows auditing is Microsoft's mechanism for tracking events on its Windows environment, knowing who triggers such events, where and when is vital for network administrators, digital forensics examiners, and even for the local users to be aware of the different events taking place on their Windows devices [1]. For example, when a user fails to sign in to Windows, the event of failed login is recorded in the event log along with the date/time and the user who triggered this event. There are scores of events that Windows records. In this article, we will focus on Windows security events and how to access and configure the Windows audit policy.
Audit Policy Categories
To display system audit policy settings, we should open the “Local Security Policy” console by going to Control Panel >> Administrative Tools >> Local security policy (see Figure 1).
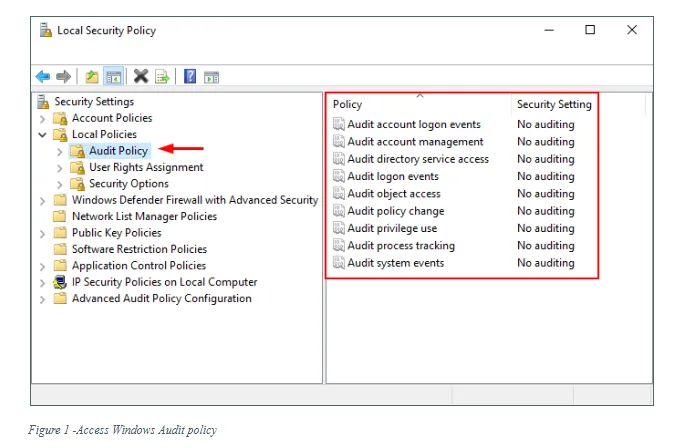
A Windows audit event will fall into one of the following nine audit policies:
- Audit account logon events: This security policy records each instance of a user logging on to or logging off from another computer where the current computer is used to validate the account. The event is logged on the domain controller when a domain user is authenticating against that domain controller; however, when a user is authenticating locally, it is stored in the computer’s Security Account Manager (SAM).
- Audit logon events: This security policy determines whether to record each instance of a user logging on to or log off from a computer. When a user has a domain account, this event is recorded on the domain controller, for local users, it is recorded on local devices. Please note this policy is different from the ‘Audit account logon events’ category. This setting is used to track the logging event to a specific server, not a domain controller.
- Audit account management: This setting is used to track user and group account modifications and is commonly used to track administrators and IT support staff. An example event would be when a user account is created, changed, deleted, disabled, enabled, locked, or unlocked in addition to recording changes to group membership.
- Audit directory service access: This setting records when a user accessed an Active Directory (AD) Domain Services (DS) object, it also records if the access was rejected. The audit is only generated for objects that have system access control lists (SACL) specified.
- Audit object access: This policy audits when a user attempts to access non-Active Directory objects. An audit is only generated for objects that have SACL specified. Examples of such objects are files, folders, shared printers, registry keys, and Windows services.
- Audit policy change: This setting audits each instance of attempts to change important security policy on a local computer such as user rights assignment policy, audit policy, account policy, or trust policy if the computer is a part of a domain controller.
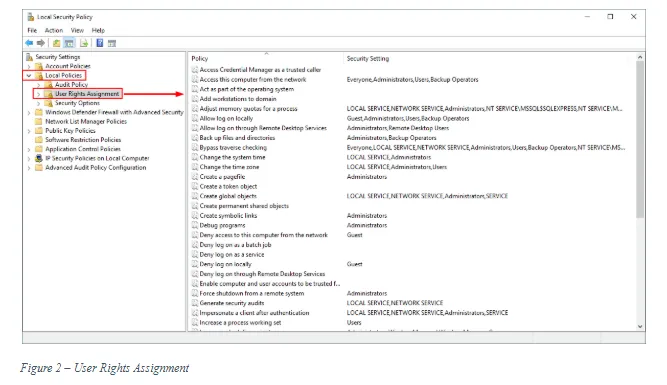
- Audit privilege use: This setting tracks the exercise of user privilege. The user privilege refers to the user rights that you find in the “Local Security Policy” under Security Settings\Local Policies\User Rights Assignment (see Figure 2).
- Audit process tracking: This setting determines whether Windows audits process-related events such as process creation, process termination, handle duplication, and indirect object access. This policy is useful to track all programs executed by the system or end-users. It can also display how long a specific program was open. This policy can be linked to “Audit logon events” policy, and “Audit object access” policy using the Logon ID or Process ID to record detailed results about specific user activities.
- Audit system events: This setting determines if Windows audits any of the following events:
9.1 When a user attempts to change system time. 9.2 When a user starts or shuts down the computer. 9.3 Attempts to load extensible authentication components. 9.4 Loss of audited events due to auditing system failure. 9.5 When the security log size exceeds the limit set by the user.
Get Microsoft Certified Solutions Associate (MCSA) Certified >>
Recommended security policy to enabled on your Windows
Windows can be configured to track different security and user management events; however, some policy settings are more important to enable than others. In this section, we will list some important audit policies to enable on a Windows device.
Password Policy
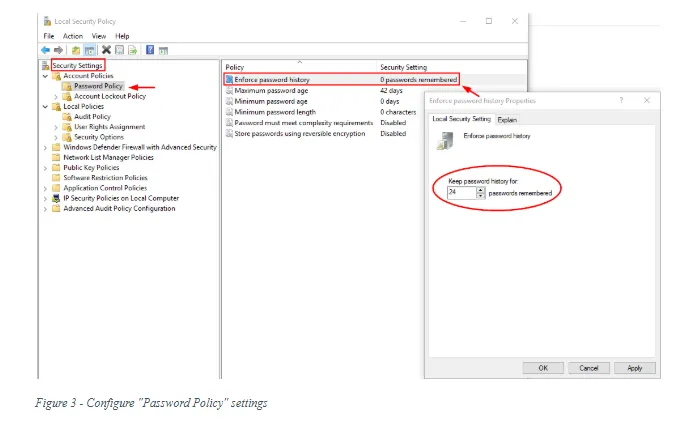
To audit user accounts policy on the local Windows system, open “Local Security Policy” >> Security Settings >> Account Policies >> Password Policy (see Figure 3).
- Enforce password history: 24
- Maximum password age: 60
- Minimum password age: 1
- Minimum password length: 14
- Password must meet complexity requirements: Enabled
- Store passwords using reversible encryption: Disabled
Account Lockout Policy
Open “Local Security Policy” >> Security Settings >> Account Policies >> Account Lockout Policy
- Account lockout duration: 15
- Account lockout threshold: 10
- Reset lockout counter after: 15
Account Logon
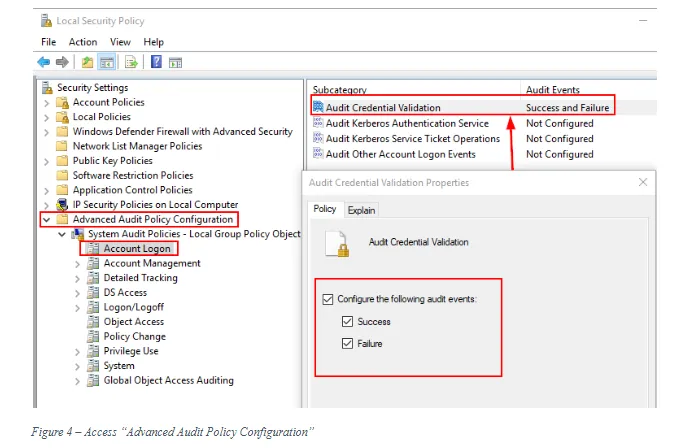
Open “Local Security Policy” >> Security Settings >> Advanced Audit Policy Configuration >> Account Logon (see Figure 4)
- Audit Credential Validation: Success and Failure
Account Management
Open “Local Security Policy” >> Security Settings >> Advanced Audit Policy Configuration >> Account Management
- Audit Computer Account Management: Success
- Audit Other Account Management Events: Success and Failure
- Audit Security Group Management: Success and Failure
- Audit User Account Management: Success and Failure
Detailed Tracking
Open “Local Security Policy” >> Security Settings >> Advanced Audit Policy Configuration >> Detailed Tracking
- Audit Plug and Play Events: Success
- Audit Process Creation: Success
DS Access
Open “Local Security Policy” >> Security Settings >> Advanced Audit Policy Configuration >> DS Access
- Audit Directory Service Access: Success and Failure
- Audit Directory Service Changes: Success and Failure
Logon/Logoff
Open “Local Security Policy” >> Security Settings >> Advanced Audit Policy Configuration >> Logon/Logoff
Audit Account Lockout: Success and Failure Audit Group Membership: Success Audit Logoff: Success Audit Logon: Success and Failure Audit Special Logon: Success
Object Access
Open “Local Security Policy” >> Security Settings >> Advanced Audit Policy Configuration >> Object Access
- Audit Removable Storage: Success and Failure
Policy Change
Open “Local Security Policy” >> Security Settings >> Advanced Audit Policy Configuration >> Policy Change
- Audit Policy Change: Success and Failure
- Audit Authentication Policy Change: Success
- Audit Authorization Policy Change: Success
Privilege Use
Open “Local Security Policy” >> Security Settings >> Advanced Audit Policy Configuration >> Privilege Use
- Audit Sensitive Privilege Use: Success and Failure
System
Open “Local Security Policy” >> Security Settings >> Advanced Audit Policy Configuration >> System
- Audit IPsec Driver: Success and Failure
- Audit Other System Events: Success and Failure
- Audit Security State Change: Success
- Audit Security System Extension: Success and Failure
- Audit System Integrity: Success and Failure
Global Object Access Auditing
No configuration is necessary.
Summary
Windows auditing provides essential information to measure how effective your security plan is. For instance, by configuring Windows audit policies properly, you can reduce the risks of unauthorized access and detect and prevent unwanted changes to your Windows system. Auditing also plays an important role in lowering the risks of data breaches and remains in compliance with different data protection laws.
Get Certified in Microsoft 365 Fundamentals [MS-900] Today >>
Further Reading
- ultimatewindowssecurity, “The Windows Security Log Revealed,” July 30, 2020, https://www.ultimatewindowssecurity.com/securitylog/book/page.aspx?spid=chapter2
- Microsoft, “Basic security audit policy settings,” July 30, 2020, https://docs.microsoft.com/en-us/windows/security/threat-protection/auditing/basic-security-audit-policy-settings




