
TL;DR
Have you ever thought of writing a program of your own or customizing a tool that you make use of regularly? To some, writing a program/tool is one of the scariest things they can imagine, especially with tons of code and the potential for errors. However, most people working in the IT industry may love to write a tool of their own. There are many scenarios where a simple program can save a lot of time. Think of an IT staff-member who would check connectivity for a list of hosts regularly throughout a day or filter log files of a system for errors and generate a report. These things would be much harder, time-consuming, and troublesome as a manual process, but if the responsible one spends a little time writing a tool that can handle all of these things, they would be automated, time-saving, and precise. This article discusses a command language interpreter, Bash, which can be used to create scripts, along with two other handy tools.
What is Bash?
Bash is the shell, or command language interpreter, for GNU/Linux operating systems. Bash is an acronym for __B__ourne-__A__gain __SH__ell. Executing Bash commands requires a terminal where the Bash commands are entered. Here are some sample Bash commands.
lstext in bold - prints the contents(files and folder) of a directory mkdirtext in bold New_Folder- creates the New_Folder pingtext in bold IP_Address - checks the connection of a host with the IP_Address rmtext in bold File - removes File cptext in bold File Destination_Directory - copies the File to Destination_Directory mvtext in bold File Destination_Directory - moves the File to Destination_Directory Touchtext in bold File_Name - create an empty file named File_Name
What is a Bash script?
A file containing Bash commands is called a Bash script. Bash scripts can be extremely simple or extremely complex. They are usually saved with the extension ".sh." Below is an example where a file is created using the nano text editor. The text in the file simply states "ping google.com," and it is saved as ping__text in bold___google.sh.
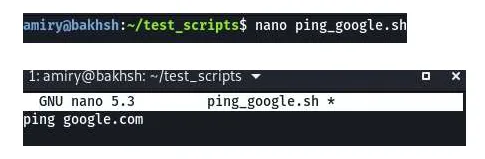
Now, by running the script, it executes the command, and the system establishes a connection with (pings) Google.
Learn More With The "Linux Fundamentals for Security Practitioners" Course >>
Why Bash scripts?!
Although it is all command-line, which is not user-friendly, it is much more powerful than GUI (Graphical User Interface) based options. There are many reasons to use Bash scripts, such as:
- It is easy to learn and easy to write programs with.
- It can execute any command easily just as they would execute in a terminal, such as ping, nano, ls, tcpdump, traceroute, convert,text in bold and much more. Other programming languages, however, require specific modules.
- It is a scripting language, and it has all the features, such as variables, flow control (conditional statements like if), iterative structures (for and while loops), and much more.
- It can be used to make very sophisticated tools.
- It can be used to run a series of commands as a single command.
- Once written, It can save a lot of time because it allows for the automation of repetitive, mundane, or complex tasks.
- It is portable (i.e., can be executed in any Unix-like operating systems without any modifications) or can simply be stored with other scripts on a USB drive and run on any Unix-based operating systems.
Despite the above advantages, sometimes, Bash scripts are very complicated to write. It is also limited to GNU/Linux operating systems, which means they can only be used on Linux-based systems. Compared to any programming language, slow execution speed is another downside for bash scripts, as a new process is launched for almost every shell command executed. These are the major limitations of Bash scripts.
What to learn for writing a Bash script?
Learning any scripting language would take a bit of time, and Bash is not an exception. For learning Bash and writing scripts using it, the following points should prove helpful:
- Learn (some) Bash commands and tools used in Linux-based machines. For book lovers, Kali Linux Revealed would be a great place to start. Cybrary also has a course called Kali Linux Fundamentals, which is also a great place to start.
- Learn the syntax for Bash, such as defining variables, taking input from the user, if-statements, loops, and so on. This helps create sophisticated tools. The following websites are helpful as well:
https://ryanstutorials.net/bash-scripting-tutorial/ https://linuxconfig.org/bash-scripting-tutorial-for-beginners
- Create while learning. Practicing while learning is extremely helpful. It can inspire ideas to use the capability better. Try to create sample scripts while learning this powerful scripting language.
Creating sample tools using Bash!
For creating tools using any programming/scripting language, one should have an idea or imagination of what he/she wants to do as there is an Einstein's quotation that says, "Imagination is more important than knowledge."
File classifier
Scenario: There is a folder called test which has 812 files in it. They are all videos, documents, pictures, and audio files. According to their extension, the mission is to create four folders in this directory named Documents, Pictures, Music, and Videos, and move the files to specific directories. At the end of the process, all documents will be in the Documents folder, images will be in the Pictures folder, audio files will be in the Music folder, and videos will be in the Videos folder.
The above scenario is simply an example of how Bash scripts can be used for sorting files. However, sorting files may be needed in various situations. Say there is a program that generates five different files each time it runs, and the user has to transfer all of them to their specific directories. This and other frequent sorting tasks are easily done using Bash, and once it is automated, there is no need to do them manually.
Solution:
- Open the working folder. In this case, it is called test.
- Right-click on it, and click on "Open in Terminal." A terminal will open in the current directory.

- Hereafter, everything is done through the terminal. Create a script file using "nanotext in bold classify_files.sh". Name the file anything, but here, it's named classify_files.sh.

- First of all, create the four folders mentioned earlier. For creating folders, use "mkdirtext in bold Documents Videos Pictures Music."
- Now, this is the time to move all images to the Pictures folder using the following commands.
mvtext in bold *jpeg Pictures mvtext in bold *gif Pictures mvtext in bold *jpg Pictures mvtext in bold *webp Pictures
- The mv command syntax is "mvtext in bold file destination_folder," which will move the file to destination_folder. The asterisk (*) is a wildcard and matches any character(s), so the commands above will move any file ending with jpeg, jpg, gif, and webp to the Pictures directory. This folder contains only these picture file types, but the commands can change for other picture file formats.
- Next, move all documents to the Documents directory using the following commands.
mvtext in bold *doc Documents mvtext in bold *docx Documents mvtext in bold *odt Documents mvtext in bold *pdf Documents mvtext in bold *rtf Documents mvtext in bold *txt Documents
- The above commands move all doc, docx, odt, rtf, pdf, and txt file formats to the Documents folder.
- After that, move all audio files to the Music directory using the following commands.
mvtext in bold *mp3 Music mvtext in bold *aiff Music mvtext in bold *aac Music mvtext in bold *wav Music
- This time mvtext in bold is used to move all files ending with mp3, aiff, aac, and wav to the Music folder.
- Then move all video files to the Videos directory using the following commands.
mvtext in bold *mp4 Videos mvtext in bold *avi Videos mvtext in bold *mpeg Videos mvtext in bold *wmv Videos
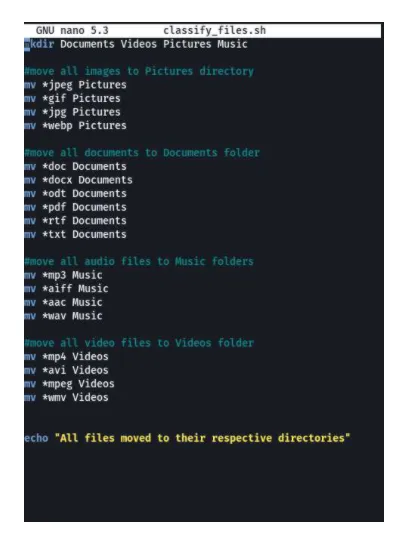
- Next, print a verification message using the command below.
echotext in bold "All files moved to their respective directories."
The command echotext in bold will print whatever is provided after that on the terminal's screen, known as stdout (standard output). So, it will print the message inside the double quotation mark. The final version of the script file looks like the following picture.
Finally, press "ctrl+xtext in bold" to close the editor, press "ytext in bold," and hit the Entertext in bold key right after that to save all the things written so far.
Let's check the process right now. The picture below is a screenshot of the directory where 812 files are located to be categorized. The respective screenshot only shows 198 files out of 812. Imagine how difficult and time-consuming it would be to find all video files among 812 files and move them to a separate directory.

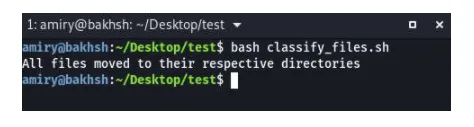
Let's return to the terminal and run the script using the command "bashtext in bold calssify_files.sh."
After pressing the Entertext in bold key, it won't take more than a 1000th of a second, and the last line in our script, which was the verification message, will be printed out on the terminal.
Let's go back to the test directory and recheck it. The effect of the script can be seen in the directory.
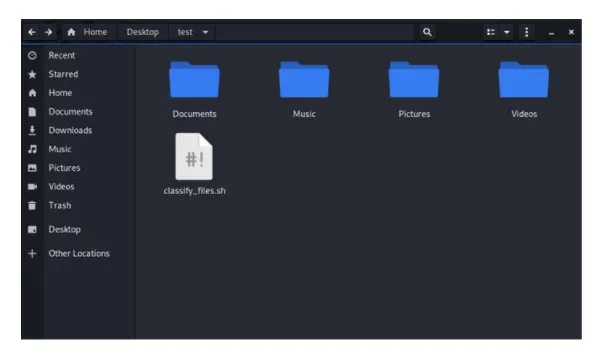
- And MISSION ACCOMPLISHED! As it is clear, four folders have been created, and the whole files have been transferred to their corresponding directories. The only file that remained outside is the script called classify_files.sh. Creating another directory called Scripts and moving all script files into that directory is a great idea. But this is an exercise for the reader! Give it a try!
A secondary interface to the tcpdump
For creating tools like this, the only thing that is needed is an idea. After that, the knowledge for applying it would be easily gathered using the internet. Recently, I was using a network-data packet analyzer called tcpdumptext in bold, which runs on the command-line interface. I was struggling with learning the flags for this command. After executing a command or two, I thought of creating an interface for this command, making using it easier. It would also be good for those who are learning it new or just want to use it without knowing more details about it.
A recently completed version of this script is available on GitHub, which can be accessed through the following link. https://github.com/karimbakhshamiry/tcpdump-interface/
Here is how this script works. As it runs it, it gives the user some choices to select from, as shown in the picture below.
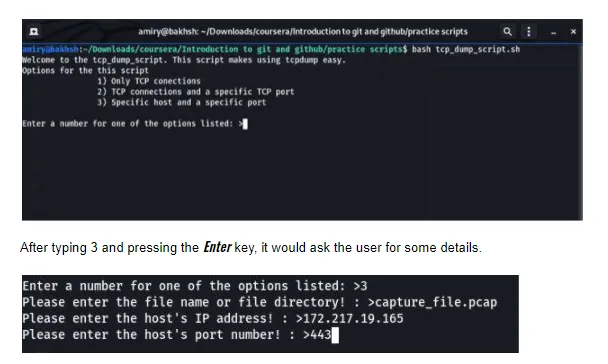
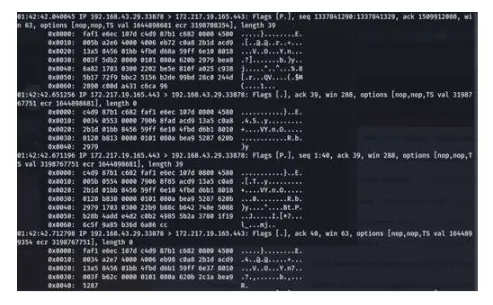
Once all the required details are given to the script, it creates the tcpdump command accordingly and executes it. Here is the output which filters all connections to 172.217.19.165 on port number 443 from the capture_file.pcap.
All in all, In the world of IT, there are many situations where scripting and automation can lighten a huge load of manual tasks. SysAdmins are mostly struggling with these types of situations, so spending a little time writing a program that can automatically do all those things can save a lot of time, and the tasks will no longer need to be done manually scripts will do them. Bash scripting can open the doors to a whole new world, so start learning this fascinating stuff today!





