
TL;DR
WHAT IS BLOCKCHAIN TECHNOLOGY?
Simply put, Blockchain is a system of having information recorded in a way that makes it difficult to change, hack, or cheat the system. A blockchain is generally a digital ledger of duplicated transactions and distributed across the entire network of systems on the Blockchain. Each block contains a number of transactions, and every time a new transaction occurs on the Blockchain, that transaction’s record is added to every participant’s ledger. This decentralized database managed by multiple participants is known as Distributed Ledger Technology (DLT).

That means if one block in a chain were changed, then it would be apparent that it has been tampered with. If hackers want to corrupt a blockchain system, they would have to change every chain's block within all the distributed versions of the chain. Bitcoin and Ethereum are examples of blockchains that are constantly growing as blocks are added to the chain, which significantly adds to the ledger's security.
Let’s take an example of Google Docs for understanding blockchain technology. When one creates a document and shares it with a few people, the document is being distributed amongst them instead of being copied or transferred. This creates a decentralized distribution chain that gives access to the document to everyone simultaneously with no delays. All modifications to the doc are recorded in real-time, making changes transparent and legit. Of course, Blockchain's concept is more complicated than a Google Doc, but this analogy is apt for our understanding.
HOW DOES BLOCKCHAIN WORK?
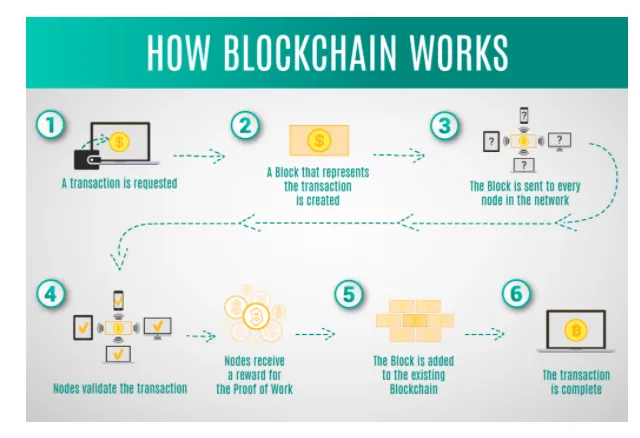
A Blockchain consists of 3 important parts or concepts:
1. Blocks
Every Blockchain consists of multiple blocks, and each of these blocks consists of three basic elements:
- Data or information in the block.
- A nonce, which is a 32-bit whole number that is arbitrary and mostly used only once. It is randomly generated when the block is created and is further used to generate a block header hash.
- A hash, which is a 256-bit number embedded with the nonce and is a function used to map the given data to a value of fixed size.
When the first block of a blockchain is created, then a nonce generates the cryptographic hash. The data that the block contains is considered to be signed and tied to the nonce and hash unless it’s mined.
2. Miners
Miners are used to create new blocks in a chain through a process known as mining. Mining a block isn’t easy on large blockchains, especially as every block has its unique nonce and hash values, and it also references the previous block’s hash in the chain. To find a possible nonce-hash combination(32-bit nonce and 256-bit hash) from the four billion possible matches, the miners use special software to find their incredibly complex “Golden Nonce” so that their block can be added to the chain. Finding golden nonces require an enormous amount of time and computing power.
It is extremely difficult to manipulate the blockchain technology because making a change to any block requires re-mining and not just the block with the change, but all the blocks that come after that block in the chain. When a block is mined successfully, and the change is accepted by all of the nodes on the network, the miner is financially rewarded.
3. Nodes
Nodes are an electronic device of any kind that maintains a copy of the Blockchain and maintains the network's functioning. Since decentralization is one of the important concepts of blockchain technology, a single organization cannot own the chain as it is a distributed ledger. Every node of a blockchain has its copy, and the network algorithmically approves any newly mined block for the chain to be updated, trusted, and verified. Transparency, another important concept of blockchain technology, ensures that all can easily view all ledger action. Each member is given a unique alphanumeric identification number that displays their transactions. Hence, blockchains can be considered to be the scalability of trust via technology.
Begin The "Penetration Testing and Ethical Hacking" Course Now >>
HISTORY OF BLOCKCHAIN TECHNOLOGY
1991 Stuart Haber and W Scott Stornetta described a cryptographically secured chain of blocks for the first time.
1998 Computer scientist Nick Szabo worked on ‘bit gold,’ a decentralized digital currency.
2000 Stefan Konst published his theory of cryptographically secured chains, plus ideas for implementation.
2008 Developers working under the pseudonym Satoshi Nakamoto released a white paper establishing a blockchain model.
2009 Nakamoto implemented the first Blockchain as the public ledger for transactions was made using bitcoin.
2014 Blockchain technology was separated from the currency, and its potential for other financial, inter-organizational transactions was explored. Blockchain 2.0 was born, referring to applications beyond currency. The Ethereum blockchain system introduced computer programs into the blocks, representing financial instruments, such as bonds. These later came to be known as smart contracts.
2015 Ethereum Second Blockchain was unveiled. Linux Foundation unveiled Hyperledger to enhance Bitcoin development.
2017 EOS.IO was unveiled by block.one as a new blockchain protocol for the deployment of decentralized applications.
2018-2020 Blockchain technology continued to evolve, depicted by an increased number of cryptocurrencies and companies leveraging the technology to enhance efficiency.
PROS AND CONS OF BLOCKCHAIN TECHNOLOGY

Let’s start with the pros of Blockchain Technology:
1. Accuracy of the chain
A network of computers that removes human involvement in the verification process approve transactions on the blockchain network, resulting in a more accurate record of information. If a computer on the network makes a computational mistake, it would only be made to one copy in the entire Blockchain. For that particular error to spread to the rest of the Blockchain, it has to be made by at least 51% of the computers in the network, which is nearly impossible.
2. Cost Reductions
With Blockchain, the need for third-party verification and its associated costs are eliminated. For example, business owners need to pay a small fee for accepting payments using credit cards as they have to be processed by banks. Whereas Bitcoin does not have a central authority and has no transaction fee as its virtual.
3. Decentralization
Blockchain is duplicated and spread across a network of computers, and so it does not store any information in a central location. Whenever a new block is added, every computer in the Blockchain’s network updates to reflect the changes. It is more difficult to tamper with information across a blockchain’s network as it is not stored in one central database. Even if a hacker tries to tamper with the information on a single block, only a single copy of the information will be compromised.
4. Efficient Transaction
Transactions placed through a central authority usually take up to a few days to get through and settle. For example, financial institutions operate during business hours only five days a week. Whereas transactions through blockchains can be completed in about ten minutes and are secure after just a few hours. Such transactions are useful for cross-border trades, usually taking much longer because of time-zone issues and payment confirmation issues.
5. Private Transaction
Many blockchain networks that operate as public databases allow the users to access details about their transactions, but they cannot access identifying information about the user making those transactions. This is what makes the blockchain networks like Bitcoin confidential in nature. When a user makes public transactions, their unique code, i.e., public key(identity), is linked to the Blockchain rather than their personal information. This action prevents hackers from obtaining a user’s personal information, which occurs when a bank is hacked.
6. Secure Transaction
Once a new transaction is recorded, its authenticity must be verified by the blockchain network. After the transaction has been validated, it is added to the Blockchain as a block. Each block contains its unique hash and the hash of the block before it. If the information on a block is edited in any way, that block’s hash changes but the hash code on the block would not. This makes it extremely difficult to change information on the Blockchain without getting noticed.
7. Transparency
The code can be modified by users on the blockchain network as long as they have computational power backing them. Since the data on the Blockchain is open-source, tampering with data becomes very difficult. With millions of computers on the blockchain network at all times, it is impossible to make a change without being noticed.
Let’s go to the cons of Blockchain Technology:
1. Technology Cost
Blockchain saves users’ transaction fees, but the technology is far from free. Bitcoin validates transactions that consume a vast amount of computational power using a “proof of work” system. The power from the bitcoin network containing millions of computers costs quite a lot of money. According to a recent study, the mining costs of even a single bitcoin vary drastically by location. Miners are rewarded with bitcoin for the time and energy they put in for adding a block to the bitcoin blockchain.
2. Speed Inefficiency
Bitcoin is an apt case study for the possible inefficiencies of Blockchain. Since Bitcoin’s “proof of work” system takes about ten minutes to add a new block, it is roughly estimated that the blockchain network can only manage seven transactions per second (TPS). Whereas other cryptocurrencies perform better than Bitcoin like Ethereum (at 20 TPS) and Bitcoin Cash (at 60 TPS).
3. Illegal Activity
While confidentiality protects users from hacks, it also allows illegal trading and activity on the blockchain network. For example, an online dark web marketplace, “Silk Road,” was operating from Feb 2011 until the FBI shut it down in October 2013. The Silk Road users were allowed to browse and make illegal purchases in bitcoins without being tracked. Since then, U.S. regulation prohibits online exchanges, especially those on the blockchain network, from full anonymity. In the United States, every online exchange must obtain information about the customer, verify their identity, and make sure they are not on any list of suspected terrorist organizations as soon as the customer opens an account.
4. Hack Susceptibility
Joseph Bonneau, an NYU computer science researcher, said that newer cryptocurrencies and blockchain networks are susceptible to 51% of attacks. The hackers can simply rent computational power, rather than buying all of the equipment.
BLOCKCHAIN USE CASES IN INFORMATION SECURITY
The major uses of Blockchain Technology in Information Security in 2020 are:
1. Securing Edge Devices with authentication
IT focus has shifted to smarter edge devices with data and connectivity, and so has their security concern. This network extension may have increased efficiency and productivity but has brought a security challenge for companies. Wider businesses are searching for ways to secure their IoT and Industrial IoT(IIoT) devices through Blockchain. It strengthens authentication, improves data attribution and flow, and aids in record management. For example, Dell delivers security services on Dell IoT Gateways and its EdgeX platform for the energy industry.
2. Improved confidentiality and data integrity
The full encryption of blockchain data ensures that the data will not be accessible to unauthorized parties. Simultaneously, in transit, which was a critical challenge in the age where data manipulation was a piece of cake. This data integrity extends to IoT and IIoT devices too. For example, IBM provides its Watson IoT platform with an option to manage IoT data in a private blockchain ledger, which is integrated into Big Blue’s cloud services.
3. Secure private messaging
Like Obsidian, which provides a messaging platform, most startups are using Blockchain to secure private information exchanged in chats, messaging apps, and social media. Obsidian’s messenger uses Blockchain to secure users’ metadata, and the user doesn’t have to use an authentication method to use the messenger. The metadata is randomly distributed throughout a ledger preventing it from being compromised.
4. Boosting or replacing PKI
Public Key Infrastructure(PKI) is a technology used for the authentication of users and devices. The basic idea of PKI is to have one or more trusted parties digitally sign documents certifying that a particular cryptographic key belongs to a particular user or device. Major implementations rely on a centralized third-party certificate authority(CA) to issue, revoke, and store key pairs. Cybercriminals then target such authorities to compromise encrypted communications and spoof identities.
Publishing keys on a blockchain enables applications to verify user identity and eliminates the risk of false key propagation.
For example, CertCoin is one of the first implementations of blockchain-based PKI. CertCoin’s public and auditable PKI has removed central authorities and uses Blockchain as a distributed ledger of domains and their public keys, and does so without a single point of failure.
5. Safer DNS
Botnets are conveniently used by cybercriminals to compromise critical internet infrastructure and bring down the domain name system(DNS) service providers for major websites. A blockchain approach to storing DNS entries removes a single, attackable target improving security. For example, Nebulis is a new project exploring the concept of a distributed DNS that will never fail even under large amounts of access requests. It uses the Ethereum blockchain and InterPlanetary File System (IPFS), a distributed alternative to HTTP, to register and resolve domain names.
6. Reduced DDoS
Gladius, a Blockchain startup, claims that its decentralized ledger system protects from distributed denial of service (DDoS) attacks, a significant claim when attacks are rising over and above 100Gbps. Its decentralized solutions protect by allowing connections to protection pools nearby to provide better protection and accelerate the content. Gladius also claims to allow users to rent out their spare bandwidth for extra money in a decentralized network. Gladius also speeds up access to the internet by acting as a content delivery network during less busy times.
CONCLUSION
Now that we have a basic understanding of what Blockchain is and how it works, it will be easier for us to understand its uses. Blockchain technology is growing with time and has a very bright future ahead of it. By 2022, the Blockchain technology business will be worth $10 billion, and by 2030, it will grow more than $3.1 trillion.
Begin The "Cyber Threat Intelligence" Course Now >>
REFERENCES:
- https://www.csoonline.com/article/3252213/6-use-cases-for-blockchain-in-security.html
- https://builtin.com/blockchain
- https://blockgeeks.com/guides/what-is-blockchain-technology/
- https://yorksolutions.net/the-future-of-blockchain-technology/
- https://theblockbox.io/examining-the-distinctions-between-distributed-ledger-technology-and-blockchain/ (Image 1)
- https://www.zignuts.com/blogs/how-blockchain-architecture-works-basic-understanding-of-blockchain-and-its-architecture/ (Image 2)
- https://tokeny.com/the-pros-and-cons-of-security-token-offerings/ (Image 3)





