
TL;DR
Google hacking, also known as Google Dorking, is a computer hacking technique. It uses advanced Google search operators to find security holes in the configuration and code that websites use. It is also useful for retrieving hidden information not easily accessible by the public.
Google Dorking involves using advanced operators in the Google search engine to locate specific text strings within search results. Some of the more popular examples are finding specific versions of vulnerable web applications.
This article will give examples of advanced Google Dorks that can help Open Source Intelligence (OSINT) gatherers and penetration testers locate exposed files containing sensitive information.
Advanced Google Dorks
Writing Google Dorks is not a straightforward process like the simple search query entered on Google's main page. The process takes some time to get used to. However, the returned results can be worth the effort. Before we begin writing advanced Dorks, it is worth noting that Google offers a powerful Advanced Search (https://www.google.com/advanced_search) that gives more specific search results with an easy to use graphical user interface (see Figure 1).

Here are some examples of Google Dorks:
Finding exposed FTP servers
Google can index open FTP servers. Use the following Google Dork to find open FTP servers.
intitle:"index of" inurl:ftp
To make the query more interesting, we can add the "intext" Google Dork, which is used to locate a specific word within the returned pages (see Figure 2).

Find email lists
It is relatively easy to find email lists using Google Dorks. In the following example, we are going to find text files that contain email lists.
filetype:txt inurl:"email.txt"

Live cameras We can use Google to find open cameras that are not access restricted by IP address. The following Google dorks retrieve live cameras web pages.
inurl:"view.shtml" "Network Camera" (see Figure 4)
"Camera Live Image" inurl:"guestimage.html"

Finding passwords
Finding passwords is the most attractive task for both legitimate and ill-intentioned online searchers. The following Google Dorks retrieve exposed passwords.
- site:pastebin.com intext:admin.password (find the text "admin.password" in the Pastebin website; this site is used by hackers to publish sensitive leaked information) (see Figure 5).

- "admin_password" ext:txt | ext:log | ext:cfg (find the text “admin-password” in exposed files of the following types: TXT, LOG, CFG) (see Figure 6).

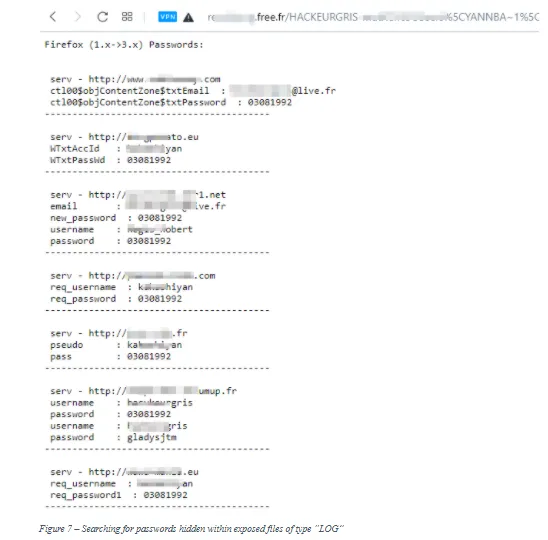
- filetype:log intext:password after:2016 intext:@gmail.com | @yahoo.com | @hotmail.com (search for all files of type "log" that contain the word "password" within them, are indexed after 2016, and contain any of the following text in their body: @gmail.com, @yahoo.com, or @hotmail.com) (see Figure 7).
Other advanced Google Dorks can be found in the following list. Try them on your own to discover what each one returns.
- site:static.ow.ly/docs/ intext:@gmail.com | Password
- filetype:sql intext:wp_users phpmyadmin
- intext:"Dumping data for table orders"
- "Index of /wp-content/uploads/backupbuddy_backups" zip
- Zixmail inurl:/s/login?
- inurl:/remote/login/ intext:"please login"|intext:"FortiToken clock drift detected"
- inurl:/WebInterface/login.html
- inurl:dynamic.php?page=mailbox
- inurl:/sap/bc/webdynpro/sap/ | "sap-system-login-oninputprocessing"
- intext:"Powered by net2ftp"
Google Dorks lists
There are different places to find ready to use Google Dorks. The first place is Google Hacking Database. This is a free public database containing thousands of Google Dorks for finding sensitive publicly available information (see Figure 8).

Other websites that list important Google Dorks are Gbhackers and Intelligence X.
Summary
This article has demonstrated how to use Google Dorks to find vulnerable servers, websites, and online cameras. Google Dorks are used by criminals to locate information about their targets and to discover easy to attack targets by searching for vulnerable websites and networks. On the good side, security researchers and friendly penetration testers use Google Dorks to find leaked sensitive information, unintentionally exposed files, and to discover vulnerable servers and web applications, so they can close these security holes before they get exploited by malicious actors.




