
TL;DR
Throughout the day, I had some infuriating internet outages that forced me to create persistent ssh tunnels with autossh (Linux only), so I can get my tunneled connection back when Cox goes back up.We are covering 5 different ways to use a double TCP-to-Reverse-SSH tunnel productively:
- Remote Access To A Linux Machine at Home
- Remote Access To Your Nessus Web Application Scanner
- Remote Access To A Windows 10 Password Cracking Machine
- Diagnosing ISP outages
- Controlling all of this via your cell phone using JuiceSSH, and even perform penetration tests/red teaming!
Thanks to the aid of an old friend who used to work at Cox, he pointed out that the issue lies “upstream,” that is, the fault of the Internet Service Provider. I will cover creating a reverse tunneled local webpage from the actual cable modem, just for him to take a look at a diagnose the error codes in this article.In the meantime, I managed to find a method to remote-control the Nessus web app scanner by creating a reverse tunnel pointing to host a webpage on my Kali Linux VM locally.All of this is accessible by my phone’s web browser and my favorite SSH client app for Android, JuiceSSH. In other words, I can hack things with my phone strong WITHOUT a NetHunter device.
Now you are going to need the following things:
- A Virtual Private Server with a publicly reachable IP address. I recommend Vultr because of their insanely low prices (throughout all of the remote-controlling of my System76 laptop with my phone, I am ending the month with an invoice of around $3.50) https://www.vultr.com/
- A Linux distribution of some sort. I run a Ubuntu 18.04 host OS with Kernel-based Virtual Machine (KVM) running Kali Linux
- Access to the commands autossh, ssh, socat, netcat, and netstat. Autossh may not be installed, install it with sudo apt-get update && sudo apt-get install -y autossh)
- Installation of the JuiceSSH app on your Android phone or some SSH client https://juicessh.com/
The difference between SSH tunneling using the SSH command, vs. the AutoSSH command, is once the tunnel “breaks” because of an internet outage, it can’t be restarted without some monitoring script written in bash or python. AutoSSH for Linux solves that trouble for us by monitoring the status of the reverse tunnel command and then immediately attempting to reestablish that connection whenever possible.For the sake of simplicity (because I apparently “get people lost” quickly), I excluded public key authentication UNTIL you can grasp the basics. Now, tunneled cleartext passwords are extremely dangerous.Especially if someone has compromised your VPS jump server and remotely ran a packet capture or happened to be sniffing the same network that you are on if your phone is connected to wifi.At the end of the article, I will show you how to switch to public/private key-based authentication so you can apply the commands and methods that you learned into logging in more securely.Now before you start, make sure you open a Vultr account or Amazon AWS Account and can log in securely using whatever method they chose. This lesson requires a fundamental understanding of sudo, chmod, chown, ssh-keygen commands. And you can take your time learning this as you do.I learned these commands faster because of my pressure to pass the Offensive Security Certified Professional Exam this coming Sunday. I needed a way to remote control my penetration testing laptops/servers while on-the-go to take care of life matters. All with the power of my phone and a single app, JuiceSSH.
Building a Tunnel to Remotely Access Your Linux Machine
From now on, the term VultrJumpServer is referring to the PUBLIC IPv4 address of whatever VPS you spun up with SSH enabled like 69.22.54.65. It could be anything that your provider gave you, but I sure as hell am not given you my jump servers IP.From your Ubuntu 18.04, Host generate your keys
sudo sussh-keygen
Then copy the keys to your Vultr VPS's authorized_keys file
ssh-copy-id root@vultrJumpServer
Now run a persistent autossh process
autossh -Nf -M 10984 -o "PubkeyAuthentication=yes" -o "PasswordAuthentication=no" -i /root/.ssh/id_rsa -R 8443:127.0.0.1:22 root@vultrJumpServer
Now we have a VPS server that has a port remotely bound on 8443, that points to our SSH service. Make sure to run
service ssh start
To ensure that the sshd is ready to be contacted for remote login.Then log in to your remote jump server with ssh and ensure that port 8443 has been bound remotely onto your jump server with the netstat -antup | grep 8443 command
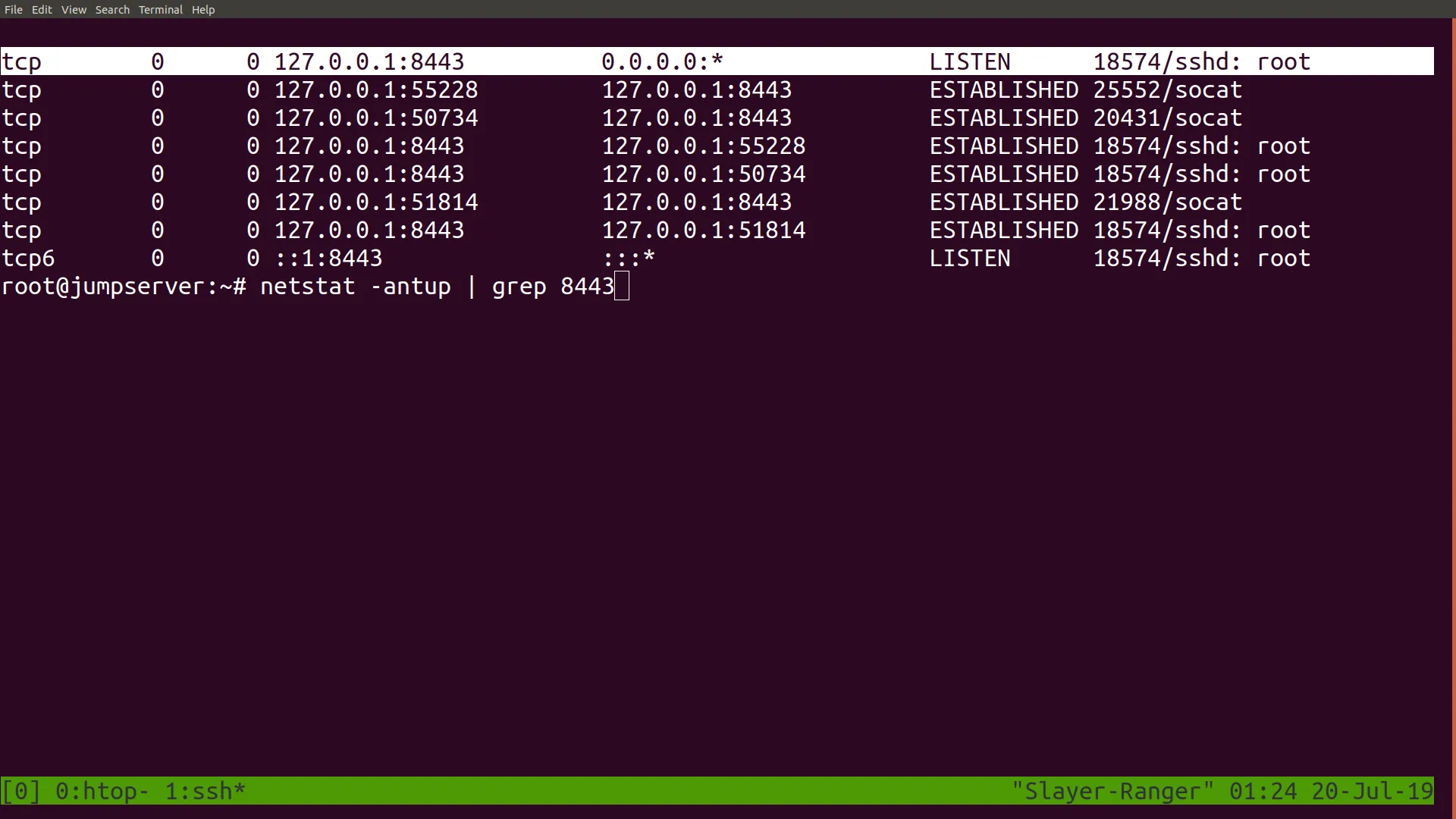
Now you can already login back into your Linux box at home with the command ssh root@localhost -p 8443; however, that requires one to first login to the jump server. If you want immediate remote access, you want to connect to a port that your public IP will allow you to forward to 8443. Since the process that bound to port 8443 is a root process, only a root user of the server may be allowed to use that tunnel.he solution to this is to start a second process as root that forwards any inbound connections on that port to root@vultrJumpServer:8443. You use socat running in the background to do this.First, open a screen session
screen -S socat1
Then within that session create a publicly reachable port that forwards to port 8443
socat TCP4-L:8080,reuseaddr,fork tcp4:127.0.0.1:8443
Then detach from session so the process continues to run with CTRL+[A]+[D];Now test this by connecting to your public IP on port 8080, and you should receive this prompt.

At this point, you can skip right to installing JuiceSSH from the app store and connecting to your home Linux machine through that tunnel.
Building a Tunnel to Remotely Access the Nessus Web GUI
I learned that configuring and installing Nessus is a pain that takes around half a day to configure fully. It dangerously uses up a lot of CPU resources as it’s installing its plugins and completely stalls my Kali Linux VM. Which has four-logical cores assigned to it and 8192MB of RAM allocated to it.Instead, I decided to go outside and get something else done (archery, picking up packages, going to meetings) instead of moping around at home.Now I installed Nessus using the .deb file from this location https://www.tenable.com/downloads/nessus.To install it
cd /root/Downloadsdpkg -i nessuspkg.debservice nessusd start
If you ran netstat -antup | grep 8834 ,you would find the web GUI local listener port on 8834 running.Now, repeating the process, we are going to remotely bind our Nessus Web GUI to a remote VPS and then have a socat proxy forward connections to that port, ultimately reaching our local Nessus installation.
autossh -Nf -M 10985 -o "PubkeyAuthentication=yes" -o "PasswordAuthentication=no" -i /root/.ssh/id_rsa -R 8081:127.0.0.1:8834 root@vultrJumpServer
Once again, you log back into your jump server and verify that the tunnel is created with the netstat -antup | grep 8081 command.With that confirmed, you then build a public-facing port, this time port 81, to forward to port 8081 on the jump-server
screen -S socat2socat TCP4-L:81,reuseaddr,fork tcp4:127.0.0.1:8081CTRL+A+D
Now, if you were to navigate to your jump servers public IP address publicly, make sure you enter it as, for example, if 69.22.54.65 is your Vultr IPv4 address then on your phone browser.
https://69.22.54.65:81/
And it should redirect you back to your Nessus installation at your home. Note that the Nessus scanner server requires HTTPS and cannot be connected to via HTTP.
Building a Tunnel to Remotely Access Your Windows GPU Password Cracker
This is a recycling of one of my old articles!Previously, we have covered reverse SSH tunneling on a compromised Windows machine to a proxy server with a public IP address that we own to reach the Remote Desktop Protocol Port.Now I just happened to have a spare laptop lying around with a dedicated video card that’s just collecting dust since I bought my new System76 laptop. (I bought it because my previous MSI’s has a BIOS poorly written to support Linux installations)
Reachable with a public IP
Now you have many choices of VPS Infrastructure as a Service provider that you can choose from,
- Amazon Web Services EC2 Cloud
- DigitalOcean Droplets
- Linode
- Vultr
- Rackspace
- Google Compute
It’s up to you on which one you choose. But I am migrating from Amazon AWS over to Vultr due to better pricing for my uses. Since I don’t need a full-blown Kali Linux mega-server running 24/7 and being charged by the hour.But be sure to sign up for one of these services first and spin up a Linux installation of your choice, either Kali, Debian, or Ubuntu.I am choosing Kali Linux despite its SYSTEM-level root by default because I have different motives than merely configuring a “jump box” to access my machines at home.I also needed:
- A general-purpose and easily configurable proxy server
- A publicly reachable IP
- A means to bypass firewall restrictions on compromised machines during a pentest by constructing a reverse SSH tunnel
- A launch repository for “malware” and pentesting tools such as plink.exe, klogger.exe, nishang (pronounced ni-shong, or “you escalate” in Chinese), No-PowerShell, BloodHound/SharpHound, rpivot.exe (which creates a unique, reversed Dynamic SOCKS proxy rather than the traditional forward Dynamic SSH SOCKS4 proxy, deployable on machines without OpenSSH installed such as older Windows machines)
- A machine with a reachable DNS address for data exfiltration via iodine and dnscat2
- A relatively sturdy host to host my Apache Tomcat 9 installation, which I consider to be a superior Java Web Application. Hosting platform given its support for Python, Jython, Java, Ruby, (All of them in the form of Servlets) and Java Server Pages which can be dynamically generated and can be embedded with malicious javascript (including service workers) to serve as launchers of drive-by malware
(I have a sub-project that I am working on, involving the instant deployment of drive-by Android malware by slipping a Dalvik Executable (.dex file) into a mobile browser cache in a onLoad() event, and using service workers to carve it back out and execute it like a Android App, a B-Variant targeting iOS iPhone devices using Swift/Objective-C/Cocoa based microkernels is also in the works).
"I excluded JBoss because JBoss is a full-stack J2EE enterprise-level deployment of Java, and it will add too much overhead and cost and unneeded features to a server that is not robust enough to support it."Let's assume that you have a public IP address granted to you from Los Angeles of 68.122.55.96 after spinning up your VPS
Let's separate the two machines as follows
TargetBox = The old gaming laptop you want to repurpose as a password cracker (and probably not worth anything else since you are too busy taking the PwK course and the piece of crap is Linux Hostile)JumpBox = The Virtual Private Server with a publicly reachable IP address you are spinning up
TargetBox: Follow this guide to enable RDP on Windows 10
https://www.groovypost.com/howto/setup-use-remote-desktop-windows-10/ but uncheck the Allow connections only from computers running Remote Desktop with Network-level Authentication because the rdesktop command is not compatible with Windows’ newer SSP/Kerberos authentication.Check that the service is enabled with the command
netstat -an | findstr LISTENING
And look for port 3389
TargetBox: Now install the OpenSSH library and Windows Linux Subsystem by following these guides.
https://www.howtogeek.com/336775/how-to-enable-and-use-windows-10s-built-in-ssh-commandshttps://www.onmsft.com/how-to/how-to-install-windows-10s-linux-subsystem-on-your-pcThe latter will give you access to the bourne-again shell, which provides you with useful commands such as grep, sort, uniq, cat, and for-loop operations as well as being able to run Windows executables still.
JumpBox: Now configure your remote VPS with a public IP for root-level logins, which is required for the creation of SSH tunnels.
First, edit the file
nano /etc/ssh/sshd_config
Then change it all to this configuration
Port 22Protocol 2HostKey /etc/ssh/ssh_host_rsa_keyHostKey /etc/ssh/ssh_host_dsa_keyHostKey /etc/ssh/ssh_host_ecdsa_keyHostKey /etc/ssh/ssh_host_ed25519_keyUsePrivilegeSeparation yesKeyRegenerationInterval 3600ServerKeyBits 1024SyslogFacility AUTHLogLevel INFOLoginGraceTime 120StrictModes yesRSAAuthentication yesPubkeyAuthentication yesIgnoreRhosts yesRhostsRSAAuthentication noHostbasedAuthentication noPermitEmptyPasswords noChallengeResponseAuthentication noX11Forwarding yesX11DisplayOffset 10PrintMotd noPrintLastLog yesTCPKeepAlive yesAcceptEnv LANG LC_*Subsystem sftp /usr/lib/openssh/sftp-serverUsePAM yesPermitRootLogin yesPasswordAuthentication yesClientAliveInterval 180UseDNS no
And give a password for root
passwd root
TargetBox: Now from the Windows powershell Administrator command-line
ssh -Nf root@68.122.55.96 -R 443:127.0.0.1:3389
-Nf tells the ssh client to run in the background and keep the connection open-R states a reverse bind port to be bound to the public proxy serverThe statement 443:127.0.0.1:3389 remotely binds to the proxy server, port 443 to your gaming laptop at port 3389
JumpBox: Login to your proxyserver and setup socat to forward port 80 (run as root) to localhost:443
Check that 443 has been bound remotely to the JumpBox by logging into it and running the command
netstat -antup | grep 443
Once you are certain that a ssh/sshd process is bound and established, our first part of the tunnel is done. Now we need to configure our socat tunnel
socat TCP4-L:80,reuseaddr,fork TCP4:127.0.0.1:443
Without having a root socat session reverse-proxying to the bound port on 443, you would not be able to rdesktop remotely by your VPS's public IP (only locally by using VNC to access the proxy server's GUI).Security-wise you might want to put something between this and the RDP authentication prompt. You can further secure this connection from onlookers scanning for vulnerable hosts by requiring certificate authentication as a socat option (by generating it via openssl).I am literally trying to dumb this down as much as possible (people tell me I confuse them already), so that topic is outside the scope of this article. Plus, you can collapse the tunnel by killing the ssh session on that gaming laptop or on the server.You: Now, from your Kali Linux machine (or Ubuntu or whatever you use), login to it through your publicly accessible proxy server to reach your Remote Desktop Protocol Prompt
rdesktop 68.122.55.96:80 -f
Now install your required NVidia drivers and download and install the hashcat binaries and you are donehttps://hashcat.net/hashcat/You're Done!If you are using Windows instead, then you simply use your Remote Desktop Client and enter 68.122.55.96:80 as the addressEnjoy your remotely accessible cracking machine WITHOUT having to rent an expensive Amazon AWS P2 GPU Instance by putting your old gaming laptop to work and paying the minimal cost with a publicly reachable reverse proxy server
List of basic hashcat commands:
Crack unshadowed Linux hashes
./hashcat64.exe -a 0 -w 4 -m 500 hashes.txt wordlist.txt
Crack NTLM/SAM hashes
./hashcat64.exe -a 0 -w 4 -m 1000 hashes.txt wordlist.txt
Crack NTLMv2 hashes
./hashcat64.exe -a 0 -w 4 -m 5600 hashes.txt wordlist.txt
Crack WPA2-PSK hashes
First, get cap2hccapx from hashcat-utils:https://hashcat.net/wiki/doku.php?id=cracking_wpawpa2Run the cap2hccapx.exe on your .cap file you got from Airodump-ngThen,
./hashcat64.exe -a 0 -w4 -m 2500 wpa.hccapx wordlist.txt
Possible Issues:
- Connection either hangs or gets rejected (check your IaaS provider’s firewall settings, your internal UFW easy-mode firewall, and your iptables configuration)
- The connection is laggy, with slow mouse and keyboard response (employ compression on the RDP session with the rdesktop -z parameter, if you need to double it up, then change the initial reverse tunnel command with an ssh -CNf with -C to employ compression as well and an optional number from 1 to 9 to dictate level of compression, possible horrible graphics warning!)
- I cannot connect to port 80 on my VPS’s public IP address (in this example, we have a PROXY forwarding from port 80 to 443 on the intermediary proxy server, for remote RDP SSH tunneled connections, you must have a service (that’s why I said using socat) running as ROOT proxying to the reverse SSH bound-port, otherwise, only the local root user of the VPS is able to use the tunnel with rdesktop 127.0.0.1:443
Building a Tunnel to Let a Friend Who Knows About ISPs (Cox Cable) Diagnose Your Internet Issues (dangerous)
I only did this for a brief moment in time. It effectively gave my friend who used to work at Cox, full access to the logs of the cable modem (not the router). But the information derived proved useful in determining that my internet outages were actually from UPSTREAM, as in, something went wrong with the Metropolitan Area Network (MAN) or Wide Area Network (WAN).
To let my friend see what is going on, I first created a reverse tunnel pointing to my LAN’s cable modem status. For my cable modem, the IPv4 address for the Status Panel webpage is https://192.168.100.1:80, so I had to redirect it to a public IP that is publicly reachable.This time I chose to remotely bind port 4444 on the jump server to my local cable modem Status Panel. Yes, this means through reverse tunneling, you can point the tunnel to OTHER IP addresses and ports within your LAN!
ssh -Nf root@vultrJumpServer -R 4444:192.168.100.1:80
Then I logged onto the vultrJumpServer and created a socat tunnel listening on port 82, redirecting to my cable modem status.
socat TCP4-L:82,reuseaddr,fork tcp4:127.0.0.1:4444
I then presented to him a webpage, assuming my public IP on the jump server was 69.22.54.65, then it would be rendered at
http://69.22.54.65:82
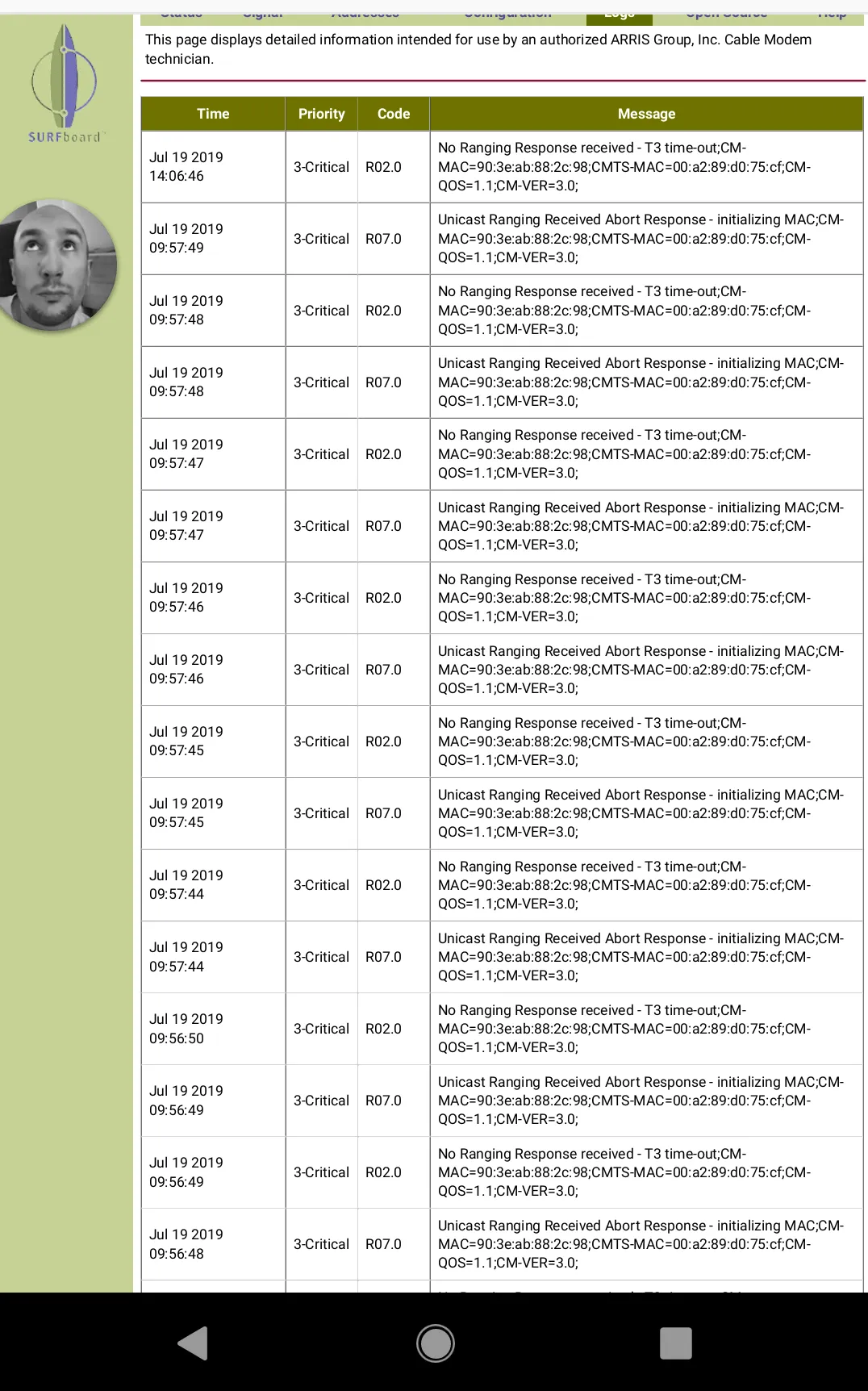
Given the amount of personal intel I noticed it logged about my network traffic, including the Cable Modems MAC address, I immediately asked him to notify me when he is done so I can promptly collapse the tunnel with the commands (on your Vultr Jump Server).
fuser -k 82/tcp 4444/tcp
But thanks to his help, we concluded:
- There is no issue with the router, which is right after the cable modem
- The issue appears to lie UPSTREAM https://pickmymodem.com/cable-modem-t3-and-t4-timeouts-error-messages-and-how-to-fix-them/
- It might be helpful to add a compressor connector to the end of the RG6 Coaxial Cable that plugs into my cable modem to better eliminate signal interference from nearby electronic devices.
Putting It Into Practice: Logging in with JuiceSSH on your Anroid Phone
First, install JuiceSSH on the Android Play App Store.In the app, create a new identity. This is basically your auto-login. Your username is your user for the Linux box’s SSHD server. Whatever you use to ssh username@localhost. Then select to enter a password (dangerous) or use an RSA private key instead.
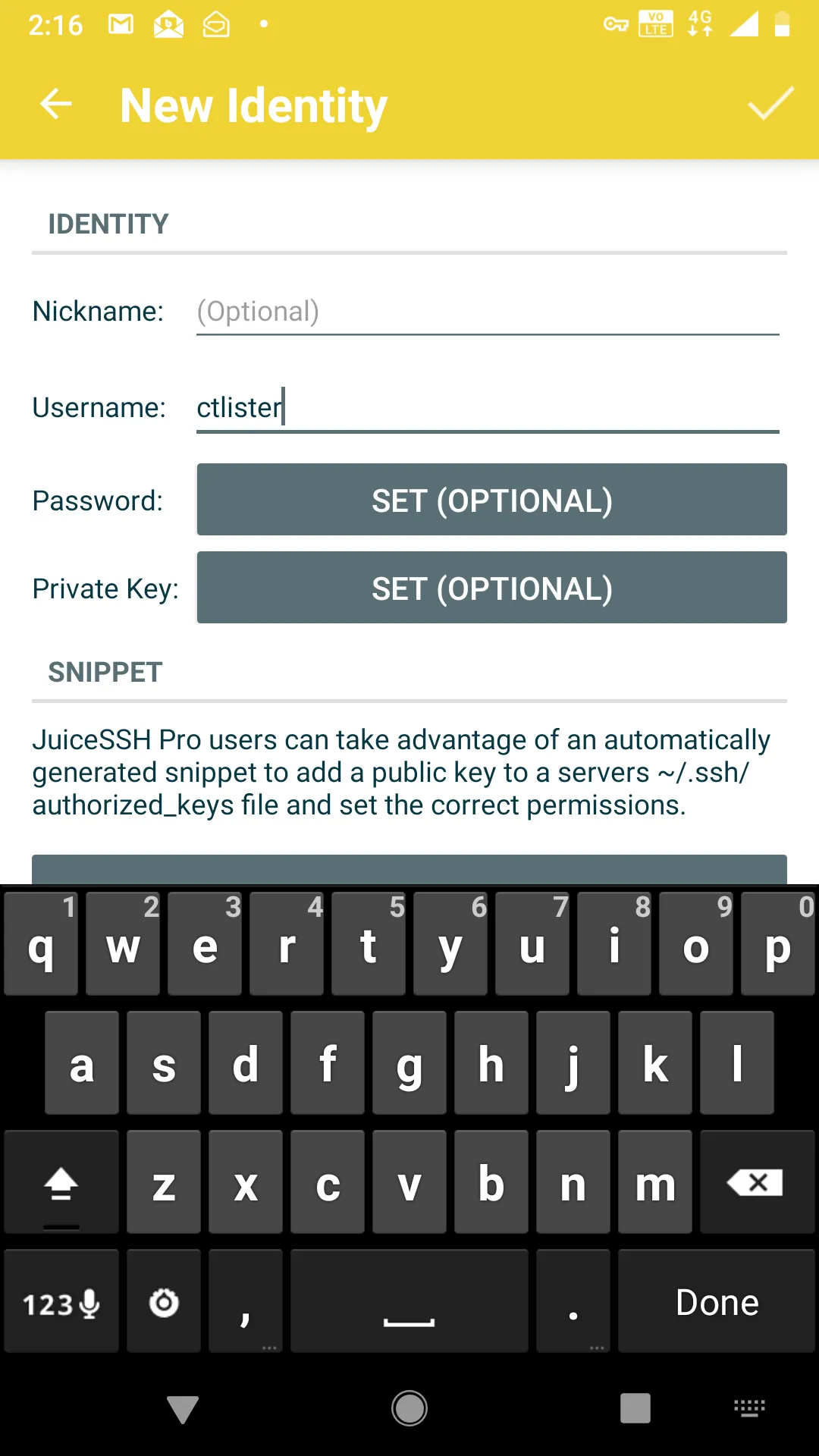
Now add a new connection, and enter the IP address and port of your VULTR JUMP SERVER and the port that is redirecting to your home Linux Machine’s SSH listener. In our previous example, I explicitly created an outbound port with socat listening on port 8080, which points to localhost:8443, which then, in turn, leads to my home Linux machine on port 22.

Click the checkmark on the top right to save the settings and make sure that you are using the correct identity for connection.At this point, connecting to your home Linux box is as easy as pressing the button, I called it, sshtunnelToSystem76, which is my Linux laptop.
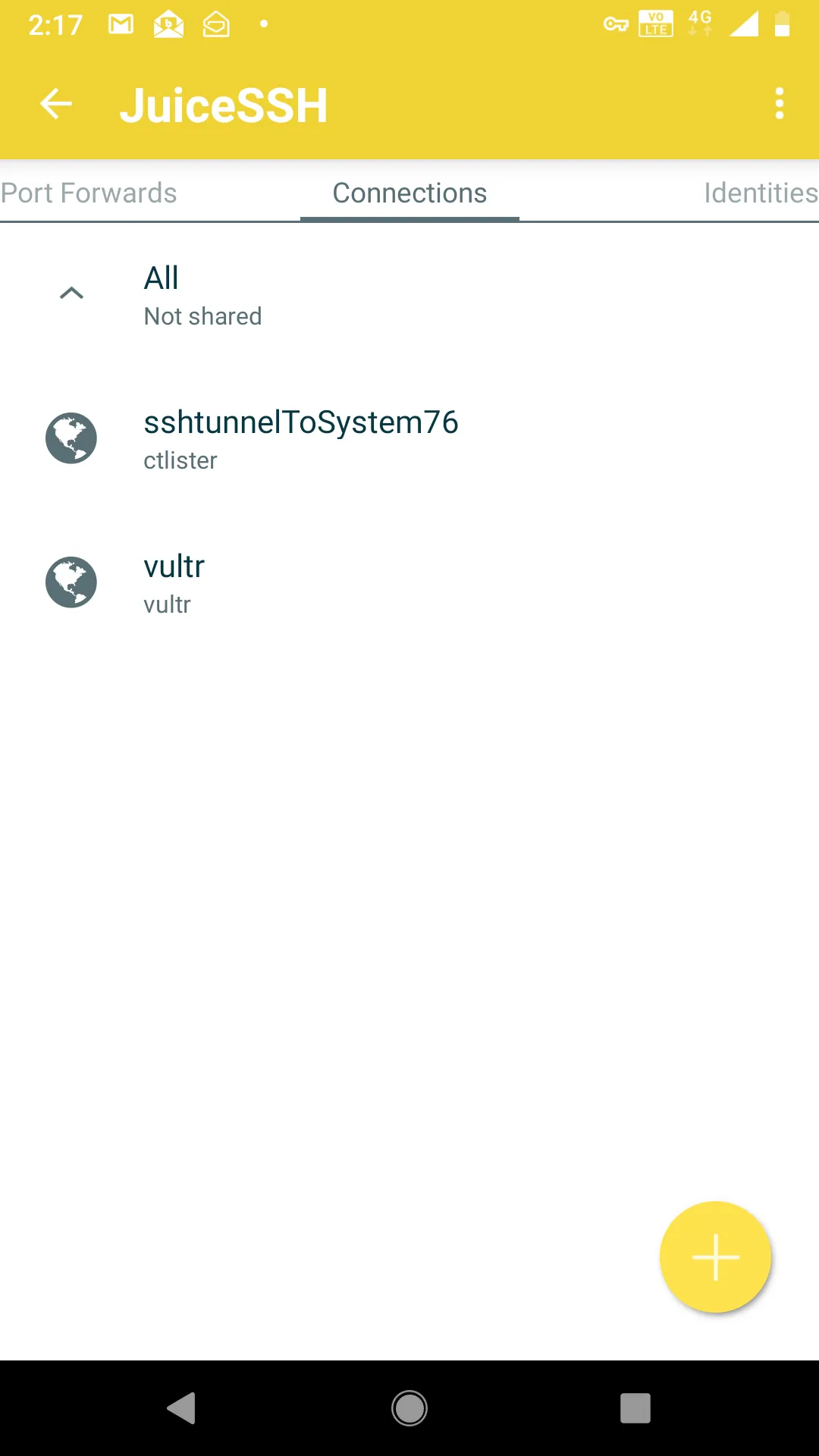
If all goes well, you should see this.
And then you will drop into the shell, for me, it’s user ctlister that is the username of localhost that accepts the connection.Now I have full control of my laptop with my cell phone. If I wanted to do some penetration testing with my cell phone remotely, like the offsec labs, I ssh root@kali or, more precisely, since the IP address in KVM of 192.168.122.84 is saved on my /etc/hosts file, it is actually ssh root@192.168.122.84 from this shell.And there you have it. I can do penetration tests and hack WITHOUT having a specific Nethunter Tablet or phone. https://www.kali.org/kali-linux-nethunter/
Switching to Public/Private Key Authentication
For safety reasons, you definitely want to switch over to key-based authentication. Remember how we generated both a private and public key with the ssh-keygen command?We can now implement that in JuiceSSH, which accepts only private RSA keys. Simply send the id_rsa file to yourself, for me it is located at /home/ctlister/.ssh/id_rsa. Copy this and email it yourself or something.
xclip -selection clipboard /home/ctlister/.ssh/id_rsa
Then send it to yourself. Go back to your ctlister identity on JuiceSSH and select Private Key
Then select the Paste tab and paste the entire RSA key within it and save it with the checkmark on the right.
Start Learning Today :
Now, the final step is to edit your /etc/ssh/sshd_config file and restart the sshd daemon.
nano /etc/ssh/sshd_config
And then change
PasswordAuthentication yes
To
PasswordAuthentication no
Then CTRL+X and Y to save it.Then restart your SSH listener
service ssh restart
Now, you have the ability to
- Push-button login back to your Linux box
- Hack using just your cell phone without rooting it or installing the Nethunter ROM (by remote-controlling Linux machines Hosts and Guests in KVM Hypervisors.
- Run maintenance on your home network





